


Identifying AI Risks
In Part 2 of our short series on building your AI Risk Management Framework, here are five real-world, proven and practical ways to identify the real risks to your AI systems.

You can read the first article in this series on building the risk management elements of an AI Management System here:

In my previous article, I introduced a framework for categorising AI risks across operational, technical, strategic and ethical dimensions. I went through how these different risk categories create a foundation for understanding what can go wrong—but we stopped short of addressing perhaps the most critical question: how do we actually identify these risks in practice?
It's a question I've asked many times in my career to organisations implementing AI risk management frameworks. The responses are telling (and often scary):
"We sit around a table, once a year and do an annual risk assessment."
"When we have an audit, we convert the findings into risks."
"We don't really have a formal process. But before every quarterly board meeting, we take the previous risk register and maybe add risks that reflect current top of mind issues"
These answers reveal a troubling gap between theory and practice. While standards like ISO 42001 and regulations like the EU AI Act clearly state organisations must "identify risks," they remain remarkably quiet on just how complex and nuanced that process really is. It's a bit like being told to "make dinner" without any insight into ingredients, techniques, or the intricacies of actual cooking. The AI Risk Management Policy your organisation develops might contain detailed sections on governance structures, documentation requirements, and management review processes—but the actual mechanics of identifying substantive risks often remains a mysterious black box, left to the imagination and diligence of the implementers.
This disconnect matters. Since the very first HazOp study1 I participated in as a junior chemical engineer, I've witnessed over and over again how risk identification becomes the hidden stumbling block that derails otherwise well-designed governance approaches. Teams either drown trying to imagine every conceivable scenario, or they fall back on traditional IT risk approaches that miss AI-specific concerns entirely. Finding the middle path—being systematic enough to catch important risks while remaining practical enough to complete the exercise—requires specific techniques that many governance frameworks simply don't provide.
Think about the challenges unique to AI risk identification. Unlike conventional software where risks might be confined to clear technical boundaries, AI risks emerge from the complex interplay between algorithms, data, human operators, and social contexts. While comprehensive resources like the MIT AI Risk Repository2 offer valuable reference points, we shouldn't mistake encyclopaedic knowledge for practical methodology. Stepping through a thousand documented risks and marking them as "present" or "not present" in your system might feel thorough, but it misses the complex, interconnected nature of how risks actually emerge in practice. It's a bit like trying to understand a computer by reading an alphabetical list of every hardware component in it—you might capture all the components, but you'd miss how they interact and function together.
The good news is that several proven approaches do work. These methods share a common thread—they combine structured analysis with creative exploration, helping teams look beyond obvious technical failures to spot subtle interaction effects. I’ll walk you through five practical approaches that can make this process more systematic and valuable. We'll begin with pre-mortem simulation, a technique I’ve used at the beginning of almost every workshop I’ve run on risk identification.

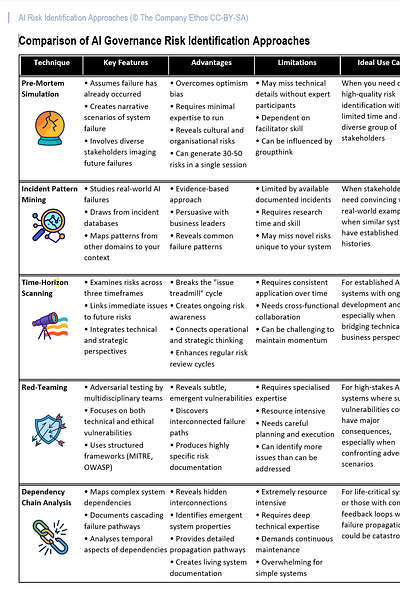
1. Pre-Mortem Simulation
Pre-mortem simulation turns traditional risk assessment inside out with a deceptively simple premise: instead of asking what might go wrong, we assume failure has already happened. This reframing breaks through our natural optimism bias—the tendency to believe our systems are more robust than they actually are.
Here's how it works: Imagine it's 18 months from now. Your AI system has failed so catastrophically that it made the front page of The Guardian. Your task isn't to defend why this couldn't happen; it's to write the story of what did happen, in vivid detail.
This approach reveals interconnected failure modes that remain invisible when examined in isolation. To illustrate, let me give you an example: Consider a hospital ICU AI-powered prediction system: in a traditional risk assessment, you might identify data quality issues and clinician override capabilities as separate concerns. But a pre-mortem might illuminate how these factors interact catastrophically. Nurses, under pressure to manage workloads, begin overriding low-priority alerts. These seemingly innocuous decisions create temporary workarounds—but also poison the very feedback data used to retrain the system. Meanwhile, new bacterial strains emerge that weren't represented in the original training data. Neither issue alone causes failure, but together they create a perfect storm where the model gradually loses predictive power while simultaneously appearing more confident in its predictions. (Take a look at this research report into a very similar scenario.)3
I love guiding teams through pre-mortems. What makes them so valuable is their ability to surface cultural and organisational risks that technical audits routinely miss. When diverse participants—from end users to engineers to legal teams—gather to collectively imagine failure, they bring unique perspectives on how systems interact with real-world conditions. Engineers might focus on algorithmic weaknesses, while nurses might identify operational shortcuts that subvert system safeguards.
The key to running an effective pre-mortem ia in creating psychological safety—people need to feel comfortable articulating uncomfortable possibilities without fear of seeming disloyal or pessimistic. The specificity of the exercise (an 18-month timeframe, a Guardian headline) grounds these discussions in concrete reality rather than vague anxieties.
From narrative to actionable risk register, the pre-mortem creates this useful bridge between imagination and systematic risk management. After participants craft their failure narratives, the facilitator guides the group through extracting specific risk elements. Each story becomes a treasure trove of potential failure points—in our scenario, the nurse who bypasses safeguards becomes "Risk #14: Operational shortcuts undermining data quality," while the system's inability to recognize new bacterial strains transforms into "Risk #27: Model drift in rapidly evolving environments."
The extracted risks carry a richness traditional approaches often lack. Rather than abstract possibilities, they emerge from contextual narratives that capture not just what might fail, but why and how that failure might unfold. The risk register that results combines technical concerns (algorithm limitations, data biases) with human factors (workflow pressures, alert fatigue) and organisational dynamics (communication breakdowns, misaligned incentives).
In practice, a two-hour pre-mortem session with diverse stakeholders can generate 30-50 high-quality risks that would never surface through conventional techniques. Each risk carries with it the narrative context that makes it meaningful—not just an item to be checked off, but a potential story of failure that participants can visualise and therefore work to prevent. The exercise transforms abstract risk identification into a concrete, collective understanding of how complex AI systems actually fail in messy real-world conditions.
If you only have a few hours, especially if the team don’t have background and experience in risk management, then pre-mortem simulation is the way to go.
Technique 2: Incident Pattern Mining
Incident pattern mining is our second technique to consider. It takes a bit more time to work through effectively. But it again operates on a simple but powerful principle: learn from others' failures before you repeat them. Like aviation investigators analysing black box recordings from crashes, we can extract invaluable insights from the growing repository of AI mishaps without having to experience them firsthand.
We must respect the past and mistrust the present if we wish to provide for the safety of the future - Joseph Joubert
This approach transforms abstract risk frameworks into concrete scenarios by studying real-world AI failures that have already occurred. The MIT AI Incident Tracker4 stands as perhaps our most comprehensive collective memory of such failures—a searchable archive documenting everything from subtle bias issues to catastrophic system breakdowns. Similar insights can be gleaned from the few published in-depth investigations of high-profile AI failures, such as the Robodebt scandal in Australia or the GM Cruise autonomous vehicle incidents (both of which I’ve written about previously).
What makes this approach so useful is its grounding in reality rather than speculation, important when you’re needing to convince business leaders why effective AI risk management is so essential. Consider an example of a small bank contemplating AI-powered mortgage assessment. Rather than starting from theoretical risks, they might search the incident database for relevant case studies:
A search for "predictive pricing" reveals Zillow's algorithmic home valuation disaster during the pandemic. Their model failed to adapt to unprecedented market changes—a clear warning about the dangers of concept drift in financial forecasting. The bank learns they'll need robust monitoring systems to detect when market conditions diverge from their model's training data.
Searching "credit scoring" uncovers Germany's Schufa credit scoring controversy, where opaque algorithms were found to discriminate based on age, gender, and address changes. This highlights the critical importance of fairness audits and transparent decision criteria in financial algorithms.
A "mortgage" query surfaces Navy Federal Credit Union's racial bias allegations, where automated underwriting technology approved white applicants at significantly higher rates than Black applicants. This prompts the bank to recognise the need for demographic testing and disparate impact analysis before deployment.
These aren't abstract risks—they're documented failures with real-world consequences. The patterns that emerge across multiple incidents reveal systemic vulnerabilities that might otherwise go undetected in theoretical risk assessments.
If you want to run this technique in practice, here’s the practical structured approach I would recommend:
First, get the team to identify analogous domains and technologies relevant to their system. This might mean looking beyond their immediate industry to find parallel situations where similar AI approaches have been deployed.
Next, they systematically search incident databases using tailored queries based on their system's technical components, data types, application domain, and intended users. Each relevant incident becomes a scenario to analyse.
For each incident, teams extract the failure modes, contributing factors, and cascading effects. They ask: "Could this happen to us? What would it look like in our context? What were the early warning signs that went unnoticed?"
These extracted patterns potentially then become specific, documented risks in your risk register. The Zillow case might generate risks like "R32: Failure to detect market anomalies leading to inaccurate pricing" or "R33: Inadequate model retraining frequency during rapid market changes."
You may want to classify these risks by their temporal relevance: direct repeats (common failures likely to recur immediately), evolutionary threats (risks that will transform as technology advances), and black swan events (rare but catastrophic scenarios). This classification helps prioritise immediate actions while maintaining awareness of emerging long-term threats.
The final step involves identifying specific indicators that would signal these risks are materialising in your own system (later these will help describe the detective controls you need). For instance, if you've identified the risk of concept drift based on Zillow's experience, you might establish monitoring for gradual increases in prediction error rates or distributional shifts in your input data.
This systematic learning from others' mistakes helps you move from abstract risk identification into a concrete, evidence-based process. Rather than imagining what might go wrong, you're analysing what has already gone wrong elsewhere—and making sure you're prepared when similar patterns emerge in your own systems.
You can also look to cautionary tales from other industries as inspiration for what could go wrong in your own context. One of my favourite podcasts is Cautionary Tales with Tim Harford, which has wonderful stories about how small events cascade into crises, like aboard Air France Flight 4475. Check it out - if you like thinking about safety and risk, then I’m sure you’ll enjoy.
Technique 3: Time-Horizon Scanning
Ok, stepping it up a gear now into an approach that takes a bit more time, at least at first, and a commitment to consistently and regularly revisit. This approach is all about thinking on different time horizons. It reflects a fairly simple and consistent observation: systems fail across different timescales, yet our risk management processes tend to fixate on what's directly in front of us. Time is often the critical factor that determines whether an organisation spots brewing problems or gets blindsided by them.
So we apply this technique by thinking on three distinct time horizons:
Horizon 1 handles the immediate and obvious—the risks visible in our dashboards and daily operations. These are the system outages, accuracy drops, and performance degradations that trigger alerts and demand immediate attention. But treating these as isolated incidents misses their predictive power. When a manufacturing AI's defect detection accuracy starts wavering, it might not just be a technical glitch—it could be the first indication of a larger shift in production patterns.
Horizon 2 reveals risks that germinate slowly, often invisible to our usual monitoring tools. These threats develop like slow-moving weather fronts, gathering force over months before their impact becomes obvious. An AI system's performance might remain technically perfect while its real-world utility gradually erodes—like a medical diagnostic tool that maintains high accuracy scores even as new treatment protocols make its recommendations increasingly outdated. Catching these risks requires deliberate effort: longitudinal analysis of system behavior, careful observation of human-AI interactions, and regular reassessment of fundamental assumptions.
Horizon 3 pushes us to confront truly transformative risks that could reshape entire operational landscapes. These aren't just bigger versions of today's problems—they're qualitatively different challenges emerging from the evolving relationship between AI systems and society. When organisations successfully navigate Horizon 3 risks, it's because they've developed the capacity to think beyond immediate technical metrics to consider how their AI systems might need to adapt to changing societal expectations, regulatory frameworks, and technological paradigms.
The real power lies not in treating these horizons as separate domains, but in understanding how they interact and inform each other. Today's technical hiccup might become tomorrow's regulatory concern, while future scenarios we imagine in Horizon 3 can reshape how we interpret the warning signs we see in Horizon 1.
Sidebar: Managing Issues versus Managing Risks
There's a subtle but critical distinction that often gets lost in the daily grind of AI operations—the difference between managing issues and managing risks. Many organisations (and I would especially call out technology-led organisations) fall into what I call the "issue treadmill." They become extraordinarily good at handling problems as they arise, developing sophisticated incident response procedures, automated detection and response, and detailed post-mortems. Their teams pride themselves on quick resolution times and comprehensive root cause analyses. They convince themselves that this is a highly effective, yet efficient approach to risk management.
But here's the truth: they're not actually managing risks—they're just getting better and better at handling failures. Eventually, those risks on Horizon 3 that they have neither anticipated nor prepared for arrive, wreaking havoc in their wake.
When applying this approach of three time horizons to generate concrete risk items, the process follows a structured progression:
For Horizon 1 risks, teams conduct regular system monitoring reviews, examining recent incidents, near-misses, and anomalies. They ask: "What patterns are emerging in our operational data? What warning signs are we seeing?" These observations might generate specific risk items like "R17: Increasing latency in fraud detection responses during peak transaction periods" or "R23: Gradual decline in sentiment analysis accuracy for non-English languages."
For Horizon 2 risks, organisations establish cross-functional workshops where technical teams meet with domain experts and business stakeholders to explore medium-term trends. They examine how changes in user behavior, data sources, or business environments might gradually undermine system performance. This might yield risk items such as "R42: Evolving customer communication styles reduce effectiveness of current NLP models" or "R51: Gradual shift in competitor offerings creating expectations our recommendation system cannot meet."
For Horizon 3 risks, forward-looking scenario planning sessions bring together strategic thinkers to consider fundamental shifts in technology, regulation, and societal norms. These sessions might identify risks like "R78: Emerging privacy regulations criminalizing current data collection practices" or "R85: Potential technological breakthrough making our current approach obsolete."
The Three Horizons approach transforms risk identification from a periodic checklist exercise into an ongoing process of temporal awareness. It helps organisations escape the reactive cycle of incident management by forcing them to lift their gaze from the immediate to the possible. A system outage isn't just an issue to resolve—it becomes a data point that might signal deeper vulnerabilities emerging in Horizon 2, or highlight strategic weaknesses that could become critical in Horizon 3. It also provides a more thorough and meaningful approach to the risk register update cycle.
I think this shift in perspective—from managing what is, to anticipating what could be— can bring about profound change in how organisations approach AI governance. Teams stop celebrating their ability to quickly resolve incidents and start asking why those incidents were possible in the first place. The focus moves from perfecting incident response procedures to identifying and addressing the conditions that make incidents possible. It's the difference between getting better at treating symptoms and actually preventing the disease.
Technique 4: Red-Teaming
Now let’s move into two techniques that require substantially more expertise, time and commitment, starting with red-teaming. Red teaming for AI systems borrows its name and core philosophy from military planning, where dedicated teams play the role of adversaries to expose vulnerabilities. While traditional software testing asks "Does this work as intended?", red teaming flips the question to "How might this be broken, corrupted, or misused—even when it's working exactly as designed?"
Imagine a war room where ethical hackers, data scientists, and domain experts gather not merely to find bugs, but to explore the boundary between use and abuse. They're playing against your AI system, thinking several moves ahead to discover vulnerabilities no conventional testing would reveal. A language model that perfectly summarises medical literature might be subtly manipulated to recommend dangerous treatments. A recommendation engine optimised for engagement might be coaxed into promoting increasingly extreme content. A fraud detection system built to protect customers might be systematically probed until patterns emerge that allow fraudsters to slip through undetected.
What makes AI red teaming different from conventional security testing is its focus on the unique vulnerabilities of AI systems. Traditional penetration testing might check if a system can be hacked, but AI red teaming explores whether a perfectly secure system might still produce harmful outputs when manipulated in subtle ways.
The most effective red teams appear to practice what security researchers call "steelmanning"—the opposite of creating strawman arguments. While strawmanning misrepresents a position to make it easier to attack, steelmanning takes the strongest possible interpretation of a system's design and still tries to find weaknesses. Red teams don't just look for obvious flaws but attempt to break systems even when they're operating precisely as designed. It's like stress-testing a bridge not just under normal conditions, but imagining a once-in-a-century flood combined with an earthquake and an unusually heavy load—scenarios it wasn't explicitly designed for but might still encounter.
For AI systems, this might mean exploring how legitimate features could be repurposed for harm, or how seemingly reasonable optimisations might lead to unintended consequences at scale. A content moderation AI might be unbreakable through obvious violations, but could be slowly acclimated to increasingly problematic content—like the proverbial frog in gradually heating water, never detecting the moment to jump.
Current best practices for AI red teaming are informed by comprehensive frameworks and guidelines developed by leading organisations such as MITRE, OpenAI, and industry groups like OWASP. These practices emphasise a multi-faceted approach to testing AI systems against diverse attack vectors, including technical and non-technical vulnerabilities. For instance, the MITRE ATLAS™ framework provides a standardised methodology for AI red teaming by aligning attack libraries with adversarial tactics, techniques, and procedures (TTPs)6. This framework helps to systematically evaluate vulnerabilities across various AI system components.
OpenAI’s approach to external red teaming7 highlights the importance of diverse team composition, including domain experts, data scientists, and ethical hackers. Their methodology involves threat modelling to prioritise areas for testing and focuses on risks such as data poisoning, model extraction attacks, and prompt injections. OpenAI has also explored automated red teaming methods to complement manual efforts, enabling scalable testing of generative AI models.
The OWASP GenAI Red Teaming Guide8 offers some practical steps for organising red team exercises tailored to generative AI systems. It includes threat modeling, vulnerability analysis, adversarial testing, bias audits, and incident response simulations. This guide emphasises the need to test not only technical flaws but also biases and fairness issues that could lead to unintended consequences in real-world applications. Microsoft’s whitepaper on red teaming generative AI products is fascinating, going through lessons learned from testing over 100 systems9. It introduces an ontology for categorising risks into traditional security vulnerabilities (e.g., outdated dependencies) and novel model-level weaknesses (e.g., prompt injections). Microsoft’s PyRIT toolkit10 further supports researchers in identifying vulnerabilities in their AI systems.
Then there are some useful gems out there, like the Guide to Red Teaming Methodology on AI Safety by Japan’s AISI11 which explains it’s recommendation to conduct red teaming exercises both before and after system deployment. Pre-release exercises focus on identifying risks during the development phase to minimise rework, while post-release efforts address emerging threats such as concept drift or data drift due to environmental changes. This guide outlines a particularly structured process that includes planning attacks, executing scenarios, and documenting findings for continuous improvement.
The translation from red team findings to risk register entries follows a structured pathway that preserves the richness of discovered vulnerabilities while making them actionable for risk management. After each exercise, a facilitator guides the team through a systematic analysis phase where raw findings are transformed into formal risk statements. A vulnerability like "The content filter can be gradually desensitised through repeated boundary testing" becomes "Risk #47: Content moderation thresholds vulnerable to gradual recalibration through systematic exposure to edge-case content." Each entry captures not just the vulnerability itself, but its potential impact, likelihood, and the conditions under which it might manifest. The most valuable aspect of this translation process is how it preserves context—the risk register doesn't just record that a vulnerability exists, but documents the specific pathways through which it might be exploited and the cascading effects that could follow.
While red teaming requires more expertise and resources than some other risk identification approaches, its ability to uncover the subtle, emergent vulnerabilities unique to AI systems makes it indispensable for organisations developing or deploying high-stakes AI.
Technique 5: Dependency Chain Analysis
The final approach in our toolkit is also the most rigorous—and arguably the most revealing when done properly. Dependency Chain Analysis peels back the layers of AI systems to expose not just individual components that might fail, but the intricate web of relationships between them that creates pathways for failure to cascade through the entire system.
I first encountered this approach not in the realm of AI, but during my early career as a chemical engineer working on North Sea oil pipeline infrastructure. There, a single pump failure could trigger a chain reaction affecting dozens of interconnected systems. We spent months mapping these dependencies, creating detailed documentation and dynamic simulations that helped engineering and operations teams anticipate how a seemingly minor issue in one subsystem might propagate to cause catastrophic failures elsewhere. I think the same principles apply with even greater force to AI systems, where dependencies can be more numerous, more subtle, and often invisible until failure occurs.
Safety is an emergent property of systems, not a component property, and must be controlled at the system level. Highly reliable components are not necessarily safe. - Nancy Leveson
Nancy Leveson’s insight12 lies at the heart of Dependency Chain Analysis—understanding that AI risks emerge not from individual components failing in isolation, but from the complex interplay between components that appear to be functioning perfectly.
Imagine a recommendation system for an e-commerce platform. On the surface, its dependencies seem straightforward: it needs customer data, product information, and purchase history to function. But dig deeper, and you discover layers of hidden dependencies. The recommendation model influences which products customers see, which shapes future purchase patterns, which in turn becomes training data for the next iteration of the model. Meanwhile, the email marketing system uses recommendation outputs to drive traffic to specific product pages, creating yet another feedback loop that affects user behavior and, ultimately, model performance. These intricate dependency chains create pathways for failure to propagate in unexpected ways. A seemingly innocent change to the email template design might subtly alter click patterns, which shifts the distribution of product interactions, which gradually biases the recommendation model, which eventually leads to declining conversion rates months later—with no obvious connection to the original change.
Mapping these relationships demands extraordinary discipline. It begins with exhaustive documentation of every component in your AI system—not just listing them, but understanding their complete operational context. For each data source, you document not only what data flows in, but its quality parameters, update frequencies, and governance requirements. For models, you capture their technical specifications, retraining schedules, performance metrics, and operational constraints. Fortunately, the work I described in previous articles for mapping your AI System Inventory is a perfect starting point.
The real complexity emerges when you start mapping dependencies at multiple levels of granularity. First-order dependencies are relatively straightforward: Model A needs Dataset B to function. But as you trace the ripple effects through the system, you discover second and third-order dependencies that create subtle, time-delayed relationships. That same Model A might influence user behavior, which affects Data Source C, which eventually cycles back to impact the very data that Model A relies on.
These relationships take shape in detailed dependency matrices that capture both direct and indirect connections. Each cell in these matrices documents not just the existence of a dependency, but its nature, strength, and potential failure modes. When done properly, these matrices become living documents that help teams anticipate how changes in one component might ripple through the entire system, creating risks that would be invisible when looking at components in isolation.
What makes this analysis particularly demanding is the need to consider the temporal dimension of dependencies. Some relationships are immediate—a model fails instantly without its input data. Others develop over time—gradual drift in user behavior slowly eroding model performance. Capturing these temporal aspects requires sustained monitoring and analysis, often spanning multiple system cycles to understand how dependencies evolve.
The investment in this rigorous approach pays off in the depth of insights it generates. Each identified dependency chain becomes a pathway for risk propagation that can be analysed, monitored, and managed. When a data source changes its format, the dependency map immediately shows which models might be affected, which applications depend on those models, and ultimately, which business processes could be impacted. This transforms abstract risks into concrete, traceable pathways that teams can monitor and manage.
But this value comes at a cost. Proper Dependency Chain Analysis requires dedicated personnel, sustained effort, and organisational commitment to maintaining and updating the analysis as systems evolve. It's not a one-time exercise but an ongoing process of discovery and documentation that becomes an integral part of AI system governance.
The approach yields very specific, actionable risk items tied directly to dependency relationships: "R93: Feedback loop between recommendation model and user behaviour creating potential for preference amplification" or "R112: Temporal dependency between data quality monitoring and model drift detection creating potential blind spots in system oversight."
Given the resources required, I generally recommend against the full formality and rigour of comprehensive Dependency Chain Analysis for most organisations building or using AI systems. But for systems making highly consequential decisions including life-critical decisions—medical diagnostics, autonomous vehicles, critical infrastructure— or for developers of large-scale foundation models, the deep insights it provides can make the difference between a robust system that degrades gracefully when components fail and a fragile one where minor issues cascade into catastrophic outcomes.
There is so much more to Dependency Chain Analysis than I can cover in one article, but if you want to learn more and apply this, then I can’t recommend highly enough the following books (two of which are published by MIT with a wonderfully free open access license to read online):
Rational Accidents, John Downer: https://direct.mit.edu/books/oa-monograph/5714/Rational-AccidentsReckoning-with-Catastrophic
Engineering a Safer World, Nancy Leveson: https://direct.mit.edu/books/oa-monograph/2908/Engineering-a-Safer-WorldSystems-Thinking-Applied
An Introduction to System Safety Engineering, Nancy Leveson: https://mitpress.mit.edu/9780262546881/an-introduction-to-system-safety-engineering/
These five approaches to risk identification can each be applied independently or woven together in a sophisticated, well-resourced risk management program, each adding its own essential strength. Rapid pre-mortem simulations reveal how organisational culture and human behaviour can undermine even technically perfect systems. Incident pattern mining can quickly help us learn from history, turning others' painful lessons into foresight. Horizon mapping keeps us alert to how risks evolve across different timescales, and invigorate the regular cycle of risk review and reporting. Red teaming challenges our assumptions about system resilience, while dependency chain analysis exposes the hidden connections that can turn minor issues into major failures.
But identifying risks is just the first stage. Think of it like discovering unmarked hazards on a map—knowing where the dangers lie is crucial, but you still need to decide which paths to take and which to avoid. Hard questions emerge when your organisation has limited resources and competing priorities: Which risks deserve immediate attention? When should you mitigate versus when should you abandon a project entirely? How do you navigate situations where addressing one risk might inadvertently amplify another?
There are some straightforward textbook prioritisation approaches, like priority rating = impact x likelihood. In our next article, we’ll start there but quickly move on to why such simple approaches to risk assessment need adaptation for AI risks. I’ll share an approach I use to incorporate "impact velocity" and feedback—dealing with how quickly an AI risk can escalate from minor concern to major crisis.
Thank you for reading, and I hope you find these approaches useful in your own daily work.
A HazOp (Hazard and Operability) study is a structured, systematic examination of a process or operation. It works by breaking down complex systems into smaller parts and applying guide words (like "more," "less," "no," or "reverse") to various parameters to imagine potential deviations from normal operations. Teams of experts then analyse these deviations to determine potential causes, consequences, and safeguards. A HazOp requires a team of diverse specialists who dedicate substantial time to methodically work through every system component and potential deviation. I don’t include it in my list of techniques because the specialised knowledge needed—from understanding neural network architectures to explainability techniques— narrows the pool of qualified participants who can effectively contribute.
https://airisk.mit.edu/
https://proceedings.mlr.press/v126/adam20a/adam20a.pdf
https://airisk.mit.edu/ai-incident-tracker
https://www.pushkin.fm/podcasts/cautionary-tales/flying-too-high-ai-and-air-france-flight-447
https://www.mitre.org/sites/default/files/2024-07/PR-24-01820-4-AI-Red-Teaming-Advancing-Safe-Secure-AI-Systems.pdf
https://openai.com/index/advancing-red-teaming-with-people-and-ai/
https://genai.owasp.org/2025/01/22/announcing-the-owasp-gen-ai-red-teaming-guide/
https://www.microsoft.com/en-us/security/blog/2025/01/13/3-takeaways-from-red-teaming-100-generative-ai-products/
https://www.microsoft.com/en-us/security/blog/2024/02/22/announcing-microsofts-open-automation-framework-to-red-team-generative-ai-systems/
https://aisi.go.jp/assets/pdf/ai_safety_RT_v1.00_en.pdf
https://direct.mit.edu/books/oa-monograph/2908/Engineering-a-Safer-WorldSystems-Thinking-Applied