


Preventing Harmful Content in AI Outputs- Part 1: Law & Governance
Part 1 of a practical guide on the law, assurance, science and engineering of preventing harmful content from AI-generated systems.

You can read the second part of this article focusing on the science and engineering of harmful content detection here:

On January 7, Mark Zuckerberg announced a dramatic reduction of Meta’s commitment to safe, moderated content on Facebook and Instagram1, following the path of Elon Musk on X2. While both executives cite such protections as content moderation and fact-checking as ‘censorship’, their decisions are clearly making social media less safe. This shift is even more concerning when you consider that they lead two of the very few companies with the resources to develop Frontier Foundation Models, Llama 3 and Grok. We have come to expect AI model providers to continually advance safety in parallel with new capabilities, but these recent moves show our expectations might be misplaced. Indeed, Zuckerberg may have even signalled his intention to such a low baseline of harm avoidance in Meta AI products some time ago:
“We must keep in mind that these models are trained by information that’s already on the internet, so the starting point when considering harm should be whether a model can facilitate more harm than information that can quickly be retrieved from Google or other search results.” - Mark Zuckerberg3
As more and more companies adopt AI, integrating AI-generated content into their customer-facing applications, this raises some concerning questions. To what extent can a company assure other businesses and end users about the safety of their AI-powered experiences? Where do the ethical and legal responsibilities lie? How can an organisation establish the kinds of robust science, engineering and governance practices to maintain safety for their customers, regardless of shifts in the broader landscape? How can they protect their reputation and mitigate harm, even if their technology providers step back from that responsiblity.
In this article, I hope to answer those questions and share some foundational practical advice from my experience along with academic research and other resources. As a fellow AI Assurance Professional, my hope is that it will help you think through the end-to-end legal, policy, governance, science and engineering aspects of this problem.
So what is the law on harmful content in AI?
Contrary to what some may believe, governments and regulators have not been waiting for tech companies to develop their own self-regulation on the safety of AI generated content. While Zuckerberg and Musk might try to frame such responsibilities as ‘censorship’ and choose to disregard them, the truth is that the prevention of content-related harm is already within well-established requirements in law and new regulations emerging. They range from the comprehensive EU AI Act4 to the US FTC consumer protection laws5 and the Australian Online Safety Framework6 to name a few.
These laws and regulations have something in common: the organisation deploying AI is ultimately accountable for the protection of users from harm, regardless of the views or compliance of their upstream technology providers views or compliance.
Let’s start with the EU AI Act7. Article 5 explicitly bans any AI application that exploits vulnerabilities due to age, disability, or socioeconomic factors. Deep-fakes, a form of harmful synthetic media, must be labelled under Article 52. ‘High-risk’ AI systems, described quite broadly in Article 6, require mandatory protections for avoidance of harm, including: a defined risk management system (Article 9); technical documentation (Article 11); data governance (Article 10); system traceability (Article 12); and meaningful human oversight (Article 14). These requirements are not vague. If your company deploys AI in a high-risk use case serving EU citizens (even if your company is not based in the EU), you must monitor content produced and have the capacity for preventing harm through meaningful human oversight and intervention. The Act has real teeth, with fines of 40 million Euro or 7% of global revenue for a breach of Article 5 and significant fines for other breaches. Stating a defense that ‘the model made me do it’ will be akin to a student’s plea that ‘the dog ate my homework.’
Again in the EU, the Digital Services Act8 adds a further layer of requirements, as practically every online platform progresses to combine AI with user-generated content. Content moderation is mandatory under the EU DSA, along with active monitoring and prevention of hate speech and self-harm content, along with mechanisms for rapid notice and takedown.
The US has not yet put in place comprehensive AI laws, and perhaps it is farfetched to expect them in the near future9, but the FTC has employed existing consumer protection laws with remarkable effect. Actions against DoNotPay and Rytr10 demonstrate that the FTC is taking a serious approach to AI-generated deception. With these two cases, it is clear that the FTC Act's prohibition on "unfair or deceptive practices" now explicitly extends to AI tools that might facilitate scams or otherwise be deceptive. This creates a practical obligation for companies using AI to ensure they have proactive safeguards against harmful outputs.
Child safety requirements are strongly enforced in many international jurisdications and they certainly apply to AI systems. Under COPPA in the U.S., if a user could use your AI platform to create or distribute explicit content or respond to a prompt involving minors, the law requires more than simple age verification. This must include controls for age-gating, content filters, monitoring, and parental consent. The Texas lawsuit against Character.AI11 is an illustration of these kinds of consumer protection requirements, in that the allegation being made is that the chatbot encouraged self-harm and delivered inappropriate content to a minor.
Australia has a different approach through the Online Safety Act 202112. The Australian eSafety Commissioner places a requirement for regular testing and immediate corrections for designated services that might use AI to generate harmful content13. This extends to search engines with integrated AI chat, requiring that generated content must not contain child sexual abuse or extremist materials. The Office of the Australian Information Commissioner framework extends to "hallucinations" - so if your AI system inadvertently generates personal data, that falls under privacy obligations too14.
These requirements are demanding, and they are not optional. At a high level, they could be summarised as the need for:
Ongoing, active monitoring to detect and prevent manipulative content, especially any content that could exploit vulnerable groups
Labelling and disclosure of synthetic generated media
Logging of generated content to enable meaningful human oversight and independent inspection
Rapid notice-and-takedown response mechanisms
Age-appropriate controls that are more than simple age gates so as to include monitoring and content filtering
The regulatory message is unambiguous: responsibility for preventing AI harm lies with you if you choose to deploy an AI-powered system to your customers. This is not in any way to absolve technology providers of their resposibility to you, but the stance they take on content safety is of no material relevance if you have not taken adequate steps yourself to protect your end-users from harm.
What are appropriate governance practices?
Building a taxonomy of potential harmful content
Effective governance starts with clearly defining what could constitute "harmful content" in your context. A simple taxonomy might include:
Hate speech and harassment: Content that targets individuals or groups based on protected characteristics like race, religion, gender, or disability. This could range from subtle discriminatory language to calls for violence.
Explicit and offensive language: More than just profanity, this might include content that's deliberately crude, graphic, or designed to shock. Context is important - content in a private chat might be harmful in public.
Misinformation and disinformation: This could range from innocent mistakes to coordinated deception. At large scale, the danger is that AI combined with social media can create convincing false narratives at scale, from fake news articles to manipulated research findings.
Violent or extremist content: Content that promotes, glorifies, or provides instructions for violence, maybe even subtle forms of radicalisation.
Self-harm and suicide content: Language that encourages, instructs, or romanticises self-destructive behaviors. AI systems can appear to empathise with and then amplify harmful thoughts.
Sexual exploitation and abuse: Any content involving minors, non-consensual sexual content, or 'deepfakes'.
Unethical behaviour promotion: Content that encourages or provides instructions for illegal or harmful activities, from scams to fraud, or even dangerous ‘life-hacks’
Privacy violations: Content revealing personal information, from doxxing (revealing true identities) to synthetic content that mimics real individuals.
Manipulation and coercion: Content that exploits psychological vulnerabilities, like AI-generated content that promotes eating disorders or dangerous medical misinformation.
Tailoring the taxonomy to your specific platform and audience of users is crucial. For instance, a kid-oriented application might prioritise filtering explicit or bullying content, while a financial or marketplace platform might focus more on scam or fraud detection. One approach is to start with a big mind-map of potential harms and narrow down to ones that are particularly relevant to the use cases that you have. An example of such a mindmap is reproduced below from the research of Wang et al.
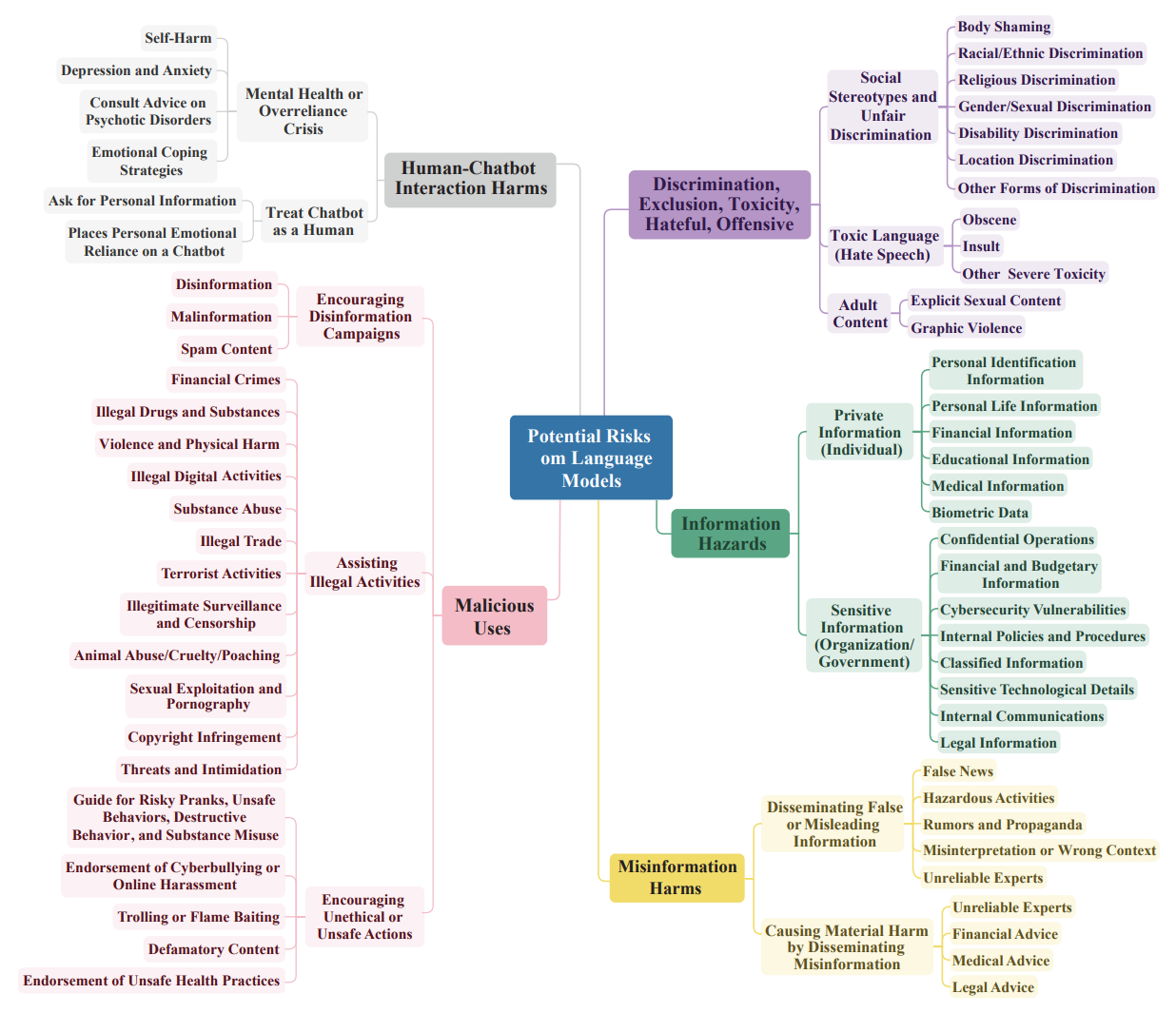
Three-level taxonomy of content-related risks involving LLMs15
Identifying risks and selecting appropriate controls
Once you have a good taxonomy defined, the next step is to identify and assess the relevant content-harm related risks. There are several different risk frameworks that can help you work through this process. I would particularly highlight Slattery's work at MIT16 which provides a really useful way to organise AI risks into distinct patterns that help predict and prevent harmful outputs before they occur (be prepared to be somewhat overwhelmed with the volume of risks in the catalog!). The MITRE AI Risk Atlas is broader with a detailed taxonomy of potential AI failures and their consequences, although in my opinion suffers from not adequately distinguishing between theoretical and real-world risk17. And IBM's risk taxonomy (although light for detail) is also worth a look as it provides a fairly straightforward categorisation approach that you could build upon to suit your needs18. Each risk exposure can be estimated by approximating the likely frequency of harmful content and its severity, and then risk-by-risk, you can set out to identify possible relevant controls.
To help with that stage, here’s a high level catalog I put together for the kinds of controls you might want to think, but remember that your specific context, scale and user audience will drive the right selection. You will likely need multiple layers that work together, each catching what the others might miss and combining technical, operational and legal functions.
1. Choose your AI provider wisely. This is critical, and there are meaningful differences (as we discuss below in the Science section), so you should:
Ask for detailed documentation of safety architectures and testing methodologies
Evaluate safety measures or APIs that may be available, but don’t assume they will be your choice for implementation
Discuss actual incident response protocols and what was learned from past safety breaches
Evaluate their approach to transparency around model updates and safety improvements
Request clear documentation of known failure modes and mitigation strategies
When evaluating providers, you can’t just take a mindset of checking boxes - you're looking for a technology partner who can prove their commitment to safety through real, demonstrated actions and transparent documentation.
2. Customisation and active monitoring. Any AI system needs clear boundaries and constant supervision because they can drift in subtle ways, and catching these shifts early is crucial:
Fine-tune models with curated datasets that are reflective of your content and safety standards (but be careful of some of the pitfalls of fine-tuning we discuss below)
Deploy real-time monitoring systems that watch for behavioral drift
Define clear safety metrics and performance thresholds that match your categories of harmful content
Create feedback loops between user reports to make ongoing model adjustments
3. Multi-layer output controls. This is about putting in place defence in depth, with a series of increasingly sophisticated safety nets, each designed to catch what might slip through the others:
First-line defense with keyword filters and basic content screening for immediate gating.
Advanced detection using classifiers trained specifically for harmful content
Specialised LLM-based safety checkers, possibly with category-specific filtering if you have specific content risks.
Automated escalation paths, alerting and kicking off protocols for handling edge cases
4. Safety testing. At some point (before your AI system goes live), you need to actively try to break your own systems, so as to make them stronger. This is invaluable for understanding how your safety systems might fail and ironing out kinks in your operational processes:
Regular red-team exercises with diverse attack scenarios
Systematic prompt injection testing
Continuous improvement based on testing results and review of any real incidents or reports.
5. User safety engagement and infrastructure. A lot can be achieved with careful user experience design, including users in the process to make safe usage seamless, intuitive and default, while maintaining robust backend controls yourself:
Safety-focused UI/UX design
Clear content warnings and user reporting mechanisms
6. Dynamic harm response framework. Lastly, you have to think through the tough judgement calls about what counts as harmful content and how you’re going to handle it when the inevitable ‘grey areas’ emerge. This may include the following:
Create a rubric that everyone agrees is adequate for classifying different types of harm and their severity
Build detailed response playbooks with the specific actions for each type of harmful content
Create and maintain a regular review cycle to look back at incidents, new information, science and engineering advances, as well as update definitions of harm
Make sure that participants in escalation paths know their roles, and ideally don’t experience a crisis escalation as their first escalation.
The key here is flexibility - just enough process and no more. Your understanding of harm and the controls put in place need to evolve as new risks and implementation challenges emerge. Lightweight processes and automation will help with that, bureacracy will only cripple your effectiveness.
Case Study: NYC “MyCity” encourages business owners to break the law19
Situation and Harm
In March 2024, investigative reporters from The Markup found that “MyCity” — an AI chatbot launched by New York City — was providing incorrect and even illegal guidance to prospective entrepreneurs. The chatbot told users they could legally fire workers who complained about harassment and take a cut of employees’ tips.
Following that advice could put NYC business owners at risk of significant legal liability, violating labour and employment laws that are meant to protect workers. The episode raised questions about the city’s due diligence in deploying and overseeing the application.
Controls
Immediate Revisions and Takedowns: After the flaw was made public, the team made quick fixes to the chatbot’s logic, removing the faulty content flows.
Policy Disclaimers and Warnings: The chatbot was updated to include more explicit disclaimers warning that the chatbot is not a substitute for professional legal advice.
Manual Review for Sensitive Topics: Certain queries triggered by the chatbot (for example, those involving labour law or licensing requirements) were identified in real-time and rerouted for human review or replaced with links to official city web pages. The city effectively built an “expert override” to ensure that up-to-date legal policies were correctly referenced.
Stricter Content Moderation: Additional filtering and QA checks were put in place, particularly around labour law and worker protection topics, to detect inaccurate or harmful statements before they could surface.If you find this useful, you may like to read an article on the skills map of an AI Assurance professional
https://about.fb.com/news/2025/01/meta-more-speech-fewer-mistakes/
https://www.wsj.com/tech/social-media-companies-decide-content-moderation-is-trending-down-25380d25
https://about.fb.com/news/2024/07/open-source-ai-is-the-path-forward/
https://artificialintelligenceact.eu/high-level-summary/
https://perkinscoie.com/insights/blog/generative-ai-how-existing-regulation-may-apply-ai-generated-harmful-content
https://www.esafety.gov.au/sites/default/files/2023-08/Generative%20AI%20-%20Position%20Statement%20-%20August%202023%20.pdf
https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=CELEX:32024R1689
https://commission.europa.eu/strategy-and-policy/priorities-2019-2024/europe-fit-digital-age/digital-services-act_en
https://www.brookings.edu/articles/ai-policy-directions-in-the-new-trump-administration/
https://www.ftc.gov/news-events/news/press-releases/2024/09/ftc-announces-crackdown-deceptive-ai-claims-schemes
https://natlawreview.com/article/new-lawsuits-targeting-personalized-ai-chatbots-highlight-need-ai-quality-assurance
https://www.esafety.gov.au/newsroom/whats-on/online-safety-act
https://www.esafety.gov.au/industry/tech-trends-and-challenges/generative-ai
https://www.oaic.gov.au/privacy/privacy-guidance-for-organisations-and-government-agencies/guidance-on-privacy-and-the-use-of-commercially-available-ai-products
https://aclanthology.org/2024.findings-eacl.61.pdf
https://arxiv.org/pdf/2408.12622
https://atlas.mitre.org/matrices/ATLAS
https://www.ibm.com/docs/en/watsonx/saas?topic=ai-risk-atlas
https://www.cio.com/article/190888/5-famous-analytics-and-ai-disasters.html
Thank you for sharing your knowledge and experience of this topic. Found it very helpful and insightful as I advance my own path for building my AI governance practice.