
AI Governance Mega-map: Operational Monitoring and Incident Management
Two control domains that focus on how we monitor, manage and respond in production - part of our mega-map of AI Governance drawing from ISO420001/27001/27701, SOC2, NIST RMF AI and the EU AI Act.

After exploring seven critical domains of AI governance, from leadership accountability to safe and responsible AI practices, we now turn to two domains that are essential for maintaining operational excellence: Operational Monitoring and Incident Management. These domains address the reality that even the most carefully designed AI systems require vigilant oversight and effective response mechanisms once deployed.
Operational Monitoring is all about putting in place the continuous visibility needed to ensure AI systems perform as intended over time. Unlike traditional software, AI systems can evolve, drift, or encounter novel situations that weren't anticipated during development. Robust monitoring controls help organisations detect subtle changes in performance, biases that emerge only in production, or unexpected behaviours that could impact stakeholders.
Incident Management complements this by establishing structured processes for responding when things don't go as planned. As AI systems become more deeply integrated into critical operations, the ability to detect, analyse, and remediate incidents becomes paramount. These controls ensure organisations can respond effectively to everything from performance degradation to more serious failures that might impact individuals or society.
Together, these two domains close the operational loop in AI governance, ensuring that systems remain accountable, reliable, and aligned with organizational values throughout their operational lifecycle. Let's examine how they work together to maintain oversight of deployed AI systems and provide mechanisms for continuous improvement.
Operational Monitoring
OM-1 System Performance Monitoring
The organisation shall implement continuous monitoring of AI system performance and behaviour in production environments. This includes automated monitoring of key performance indicators, tracking of system outputs, detection of anomalies or degradation in performance, and validation that systems operate within defined parameters. The organisation must maintain documentation of monitoring results, performance trends, and actions taken to address identified issues. Monitoring activities shall be proportional to the system's risk level and complexity.
OM-2 Event Logging
The organisation shall maintain comprehensive logs of AI system events and operations throughout their lifecycle. Logging systems must capture relevant operational data including system usage, input data references, and verification of results. Logs must be retained for required retention periods, protected from unauthorised access or modification, and made available to authorities when required. The organisation shall ensure logging systems enable effective compliance verification and support incident investigations.
OM-3 Continuous Improvement
The organisation shall establish and maintain a systematic approach to continuous improvement of AI systems throughout their operational lifecycle. This includes implementing processes to gather and analyse performance data, user feedback, and operational metrics to identify opportunities for enhancement. The organisation shall maintain documented improvement plans that outline specific objectives, timelines, and success criteria. Regular reviews must be conducted to evaluate the effectiveness of improvements and identify new areas for optimisation. The organisation shall ensure that improvement initiatives are prioritised based on operational impact and risk considerations, with clear processes for implementing and validating changes.
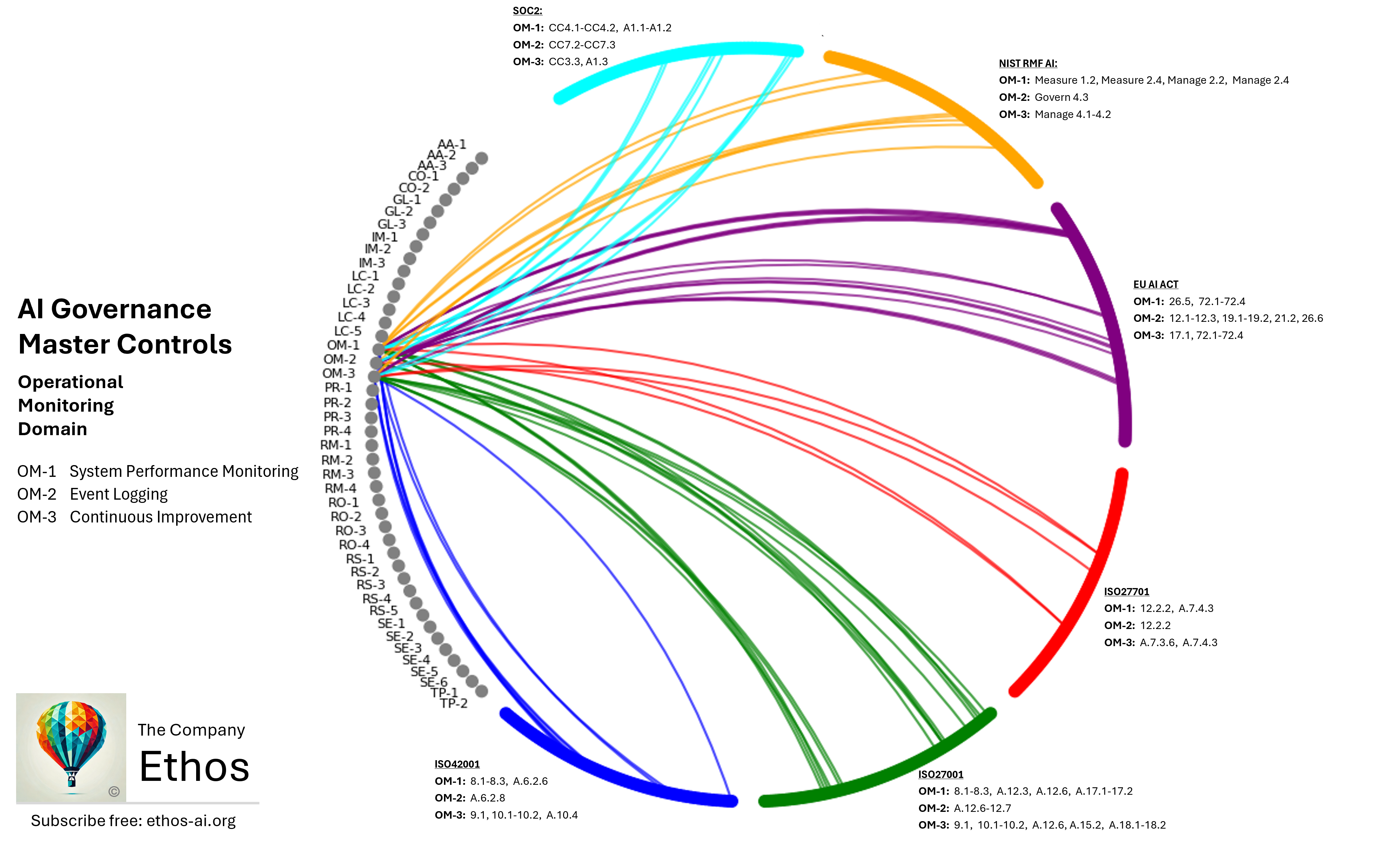
Operational monitoring is about how organisations observe and maintain AI systems in production. Unlike traditional software, where monitoring focuses largely on uptime, error rates, and resource usage, AI systems also require continuous scrutiny of model performance, data integrity, and potential drift from intended behaviours. The frameworks—ISO 42001, ISO 27001, ISO 27701, the EU AI Act, NIST AI RMF, and SOC2—collectively emphasise that operational monitoring must go beyond the technical layer, encompassing a broader set of performance metrics, logging practices, and continuous improvement processes that align with organisational objectives as well as evolving regulatory requirements. By implementing systematic performance monitoring (OM-1), detailed event logging (OM-2), and structured continuous improvement (OM-3), organizations can detect subtle shifts in AI behaviour, trace and correct anomalies, and iterate toward better performance and reliability.
OM-1: System Performance Monitoring
System performance monitoring in AI contexts demands tracking not only basic operational metrics, such as latency and throughput, but also AI-specific indicators like model accuracy, decision boundaries, and drift patterns. ISO 42001 (8.1–8.3, A.6.2.6) explicitly calls for continuous validation that systems operate within defined parameters. ISO 27001 (8.1–8.3, A.12.3, A.12.6, A.17.1, A.17.2) provides the foundational security measures—like availability management and incident handling—that support AI monitoring. ISO 27701 (12.2.2, A.7.4.3) extends these controls to ensure privacy obligations are met in real-time oversight. Meanwhile, the EU AI Act (26.5, 72.1–72.4) mandates ongoing post-market monitoring for high-risk AI systems, reinforcing the importance of proactive detection of anomalies or performance degradation. NIST AI RMF (Measure 1.2, Measure 2.4, Manage 2.2, Manage 2.4) further details how organisations can baseline behaviours and detect drift, while SOC2 (CC4.1, CC4.2, A1.1, A1.2) requires these monitoring activities to be documented, auditable, and scaled to the system’s risk level. In practice, this means implementing automated pipelines that continuously capture relevant metrics, issue alerts when thresholds are crossed, and log all interventions or remediation actions.
OM-2: Event Logging
Event logging in AI systems extends traditional logging practices by capturing the contextual data needed to understand how and why AI decisions were made. ISO 42001 (A.6.2.8) highlights the need to record system events across the entire AI lifecycle—model training, inference, and updates. ISO 27001 (A.12.6, A.12.7) similarly covers log management and secure retention, ensuring logs are protected against unauthorised access or tampering. ISO 27701 (12.2.2) adds privacy considerations, requiring that logs containing personal data or sensitive inputs are handled in compliance with data protection obligations. The EU AI Act (12.1–12.3, 19.1–19.2, 21.2, 26.6) enforces particularly stringent logging requirements for high-risk AI, demanding traceability of decision pathways and the ability to produce logs for regulatory inspections. NIST AI RMF (Govern 4.3) frames these logs as crucial for accountability and incident response, and SOC2 (CC7.2, CC7.3) ensures that organisations implement formal procedures for log retention, analysis, and reporting. Operationally, organisations might deploy specialised logging services that capture not only system usage but also model inputs, confidence scores, and key decision variables, thereby providing the forensic detail needed for both technical debugging and regulatory compliance.
OM-3: Continuous Improvement
Because AI systems often evolve over time—through new data, retraining, or parameter tuning—continuous improvement must be an ongoing, structured process rather than an ad-hoc exercise. All of the ISO management standards place a heavy emphasis on establishing mechanisms for continuous improvement. ISO 42001 (9.1, 10.1, 10.2, A.10.4) prescribes a systematic approach for gathering feedback and performance data, then using it to drive iterative enhancements. ISO 27001 (9.1, 10.1, 10.2, A.18.2, A.15.2, A.12.6, A.18.1) reinforces these practices by integrating them into broader information security and change management processes, while ISO 27701 (A.7.4.3, A.7.3.6) addresses how improvements must also respect privacy obligations. The EU AI Act (17.1, 72.1–72.4) underscores the necessity of ongoing updates for high-risk AI systems, ensuring they remain aligned with current best practices and risk thresholds. NIST AI RMF (Manage 4.1, Manage 4.2) positions continuous improvement as the culmination of mapping, measuring, and managing AI risks, creating a feedback loop that fosters incremental enhancements. Meanwhile, SOC2 (CC3.3, A1.3) ensures that these improvements are documented, tracked, and integrated into the organisation’s overall governance framework. In practice, this often means establishing cross-functional “improvement sprints” that analyse performance data, user feedback, and operational logs, then apply controlled changes to models or processes—always with clear documentation and risk assessments.

Incident Management
IM-1 Incident Detection and Response
The organisation shall establish and maintain a comprehensive incident management process for AI systems. This process must include mechanisms for detecting incidents, assessing their severity, implementing immediate response measures, and conducting thorough investigations. The organisation shall maintain documented procedures for incident response, ensure adequate resources are available for incident handling, and verify that response teams have appropriate expertise. Response procedures must address both technical and privacy-related incidents, with specific provisions for high-risk AI systems.
IM-2 Incident Reporting and Notification
The organisation shall implement processes for timely reporting of serious incidents to relevant suppliers, customers, authorities, affected individuals, and other stakeholders as required by applicable regulations or internal policy. This includes maintaining clear notification timelines based on incident severity, ensuring completeness and accuracy of incident reports. The organisation must document all notifications and maintain evidence of compliance.
IM-3 Incident Analysis and Improvement
The organisation shall analyse incidents to identify root causes, assess the effectiveness of response measures, and implement improvements to prevent recurrence. This includes conducting post-incident reviews, documenting lessons learned, updating incident response procedures based on experience, and verifying the effectiveness of corrective actions. The organisation must maintain records of all incident analyses and resulting improvements.

Incident Management for AI systems is in my experience, possibly the most critical and challenging areas of AI governance, because it requires quite a rethink on how your organisation adapts conventional incident response protocols to the distinct complexities of AI. The most difficult challenge is often to answer a question that at face value seems deceptively simple: ‘What is an AI incident?’ You see, unlike traditional software, where an incident might manifest as a clear outage or bug, AI incidents can arise from subtle shifts in model performance, data quality issues, or emergent biases. As a result, the frameworks—ISO 42001, ISO 27001, ISO 27701, the EU AI Act, NIST AI RMF, and SOC2— all place significant emphasis on comprehensive detection mechanisms, clear reporting protocols, and continuous improvement processes tailored to the unique characteristics of AI. This demands an approach that combines technical monitoring with an understanding of AI’s evolving nature, one that requires robust detection and response mechanisms (IM-1), transparent reporting protocols (IM-2), and iterative improvement cycles (IM-3).
IM-1: Incident Detection and Response
When an AI system begins behaving unexpectedly, organisations must be equipped to detect anomalies quickly and respond with appropriate measures. ISO 42001 (A.8.4) highlights the importance of establishing a robust incident management process, ensuring that response teams have both the technical and domain-specific expertise to address AI-related issues. ISO 27001 (A.16.1, A.12.7) provides foundational security incident response guidelines, while ISO 27701 (16.2.1, A.7.3.7, B.8.5.4) extends these to privacy incidents and data protection considerations. The EU AI Act (73.6) underscores the heightened stakes for high-risk AI systems, requiring specialised incident handling that accounts for potential societal impacts. NIST AI RMF (Manage 4.3) similarly advises organisations to blend traditional IT response playbooks with AI-specific insights, ensuring a thorough investigation of root causes. SOC2 (CC7.4, P6.1, P6.2) completes this picture by insisting on documented procedures, adequate resources, and clear accountability for incident response. Cross-functional incident response teams are needed capable of triaging issues that might be as simple as a data ingestion error or as complex as a model drifting from its intended decision boundaries.
IM-2: Incident Reporting and Notification
AI incidents can have far-reaching consequences, making prompt and transparent reporting essential. ISO 42001 (A.8.4) calls for clear notification pathways, ensuring that relevant stakeholders are informed when serious incidents occur. ISO 27001 (A.16.1, A.16.2) provides the foundation for defining incident severity levels and notification timelines, while ISO 27701 (16.2.2, B.8.5.4, B.8.5.5) adds data protection requirements that ensure individuals and authorities are alerted when privacy-related incidents occur. The EU AI Act (73.1–73.5, 73.9, 73.10) raises the bar for high-risk AI systems, mandating that organisations communicate swiftly with regulators and affected parties if AI failures could endanger public safety or fundamental rights. NIST AI RMF (Manage 4.3) supports this by framing notification as part of a broader governance process, while SOC2 (P6.3, P6.4) underscores the need for thorough documentation and verifiable compliance with incident reporting rules. Incident registers need to be setup and maintained to detail the nature of the incident, the severity rating, notification deadlines, and the exact content of disclosures made to regulators, customers, or affected individuals.
IM-3: Incident Analysis and Improvement
Because AI systems can learn and adapt over time, resolving an incident often requires more than a simple “bug fix.” ISO 42001 (A.8.4) stresses post-incident reviews that identify root causes and recommend broader improvements. ISO 27001 (A.16.3) aligns with this by requiring lessons learned to be fed back into organisational processes, and ISO 27701 (16.2.1) extends the same principle to privacy incidents, ensuring data handling procedures evolve in response to newly discovered vulnerabilities. The EU AI Act (73.6) reinforces the importance of iterative improvement for high-risk AI systems, while NIST AI RMF (Manage 4.3) positions incident analysis as a cornerstone of the “Manage” function—closing the loop on risk management. SOC2 (P6.5) ensures that documented evidence of these analyses is retained and that any subsequent improvements are properly implemented and validated. In practical terms, this might involve updating training data, refining model architectures, or revising operational monitoring thresholds, all guided by the insights gleaned from incident investigations.

We’re nearing the end of our journey through the twelve master control domains of AI governance, with just three domains remaining: Assurance & Audit, Third Party & Supply Chain, and Transparency & Communication. We're close to having a complete picture of what robust AI governance looks like in practice.
In my next article, I'll explore how Assurance & Audit provides the verification mechanisms needed to validate that controls are operating effectively. Then I’ll examine how Third Party & Supply Chain controls address the complex web of dependencies in modern AI systems, where components, data, and models often come from multiple sources. And finally, we'll dive into Transparency & Communication, exploring requirements for how organisations can clearly convey the capabilities, limitations, and impacts of their AI systems to diverse stakeholders.
To complete this series, I'll also be sharing the source code and content that powers these mappings, allowing you to tailor the control frameworks to your specific organisational needs and create your own chord diagrams for visualising control relationships. With those tools, you can adapt these principles to your unique context, whether you're implementing AI governance for the first time or refining an existing program.
I encourage you to subscribe to ensure you receive these final insights and tools.
.
Thanks for sharing James. I got a “not-found” error for Git-Hub repository.